Aurora RAG Chatbot
Technical Lead (POC) — RAG Assistant for ISTE Aurora Fest
Overview
Designed and built a RAG system to handle real-time event queries with low latency and high concurrency. Served as the primary interface for 400+ attendees and supported dynamic updates from event coordinators via a Google Sheets CMS.
Key Engineering Decisions
- Multi-Tier Caching (L1 + L2 + Semantic): Combined exact match (Redis) and embedding-based similarity caching to reduce LLM calls and achieve sub-20ms responses for repeated queries.
- Cross-Encoder Reranking: Used
ms-marco-MiniLM-L-6-v2to rerank retrieval results, improving answer precision at a ~50–100ms latency cost. - Dynamic CMS (Google Sheets): Built a Google Sheets CMS with background embedding refresh to support zero-downtime content updates by non-technical event coordinators.
- Async Backend Design: Built an async FastAPI pipeline supporting high concurrency with only 2 workers while maintaining stable latency.
Screenshots
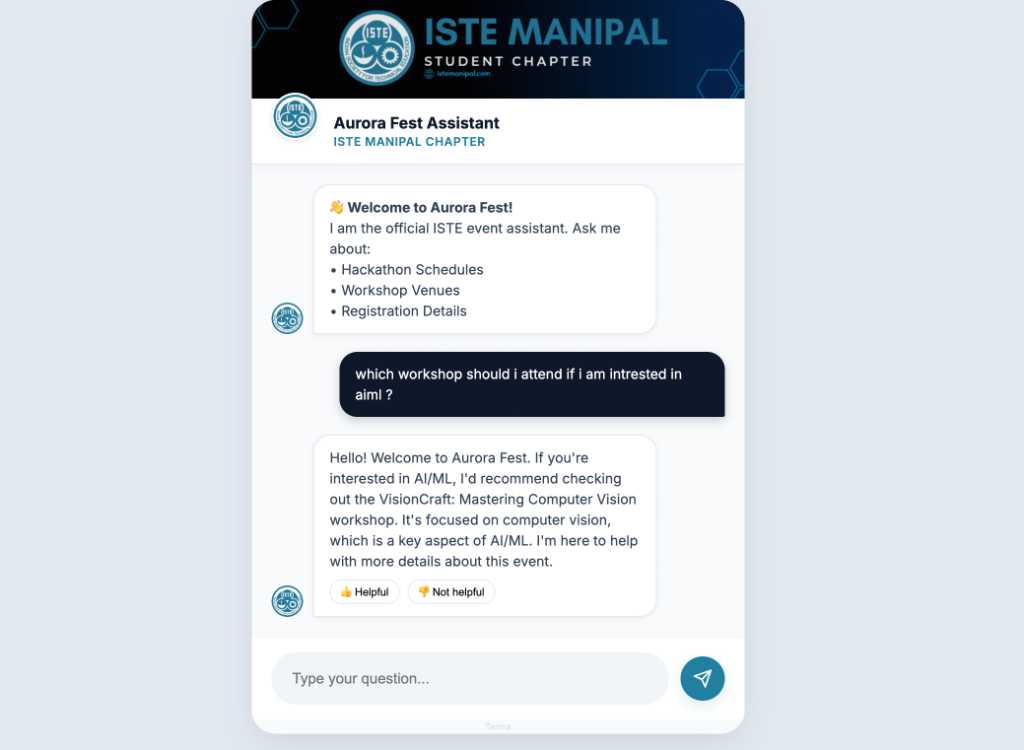
Chat interface maintaining stable response times with custom RAG pipeline.
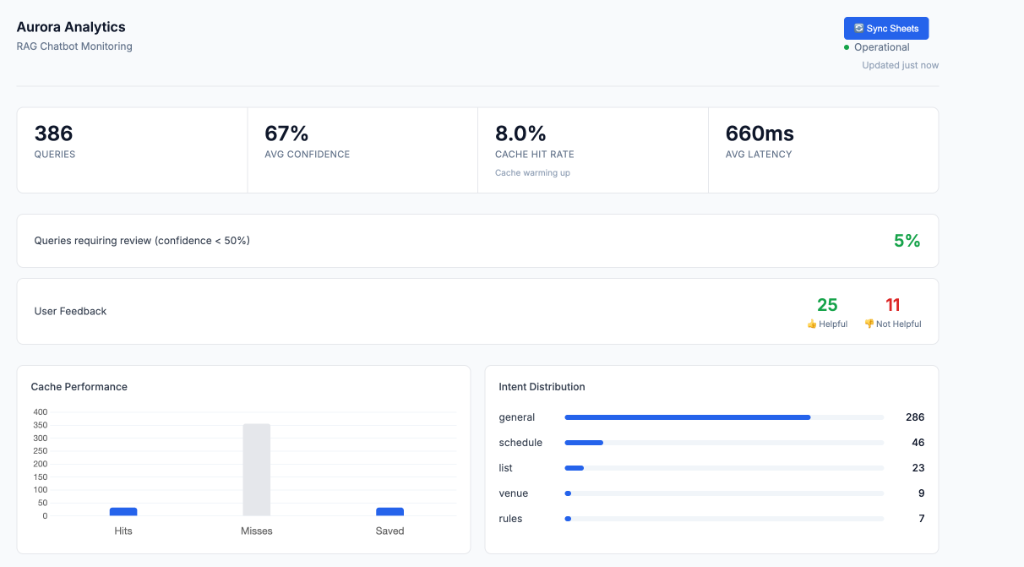
Real time analytics dashboard showing intent distribution, with 'General' and 'Schedule' as highest traffic intents.
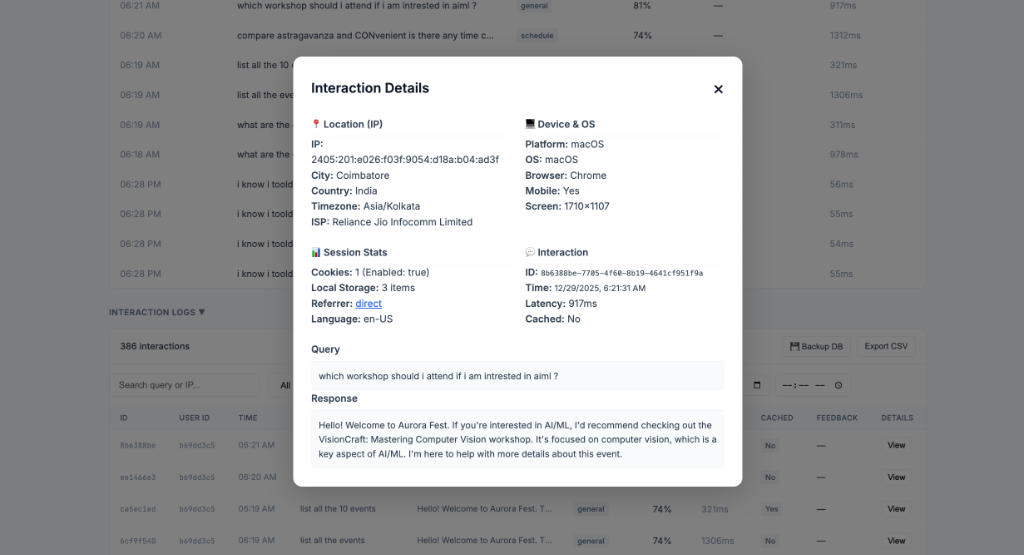
User telemetry revealing mobile traffic distribution, leading to late stage mobile UI optimization.
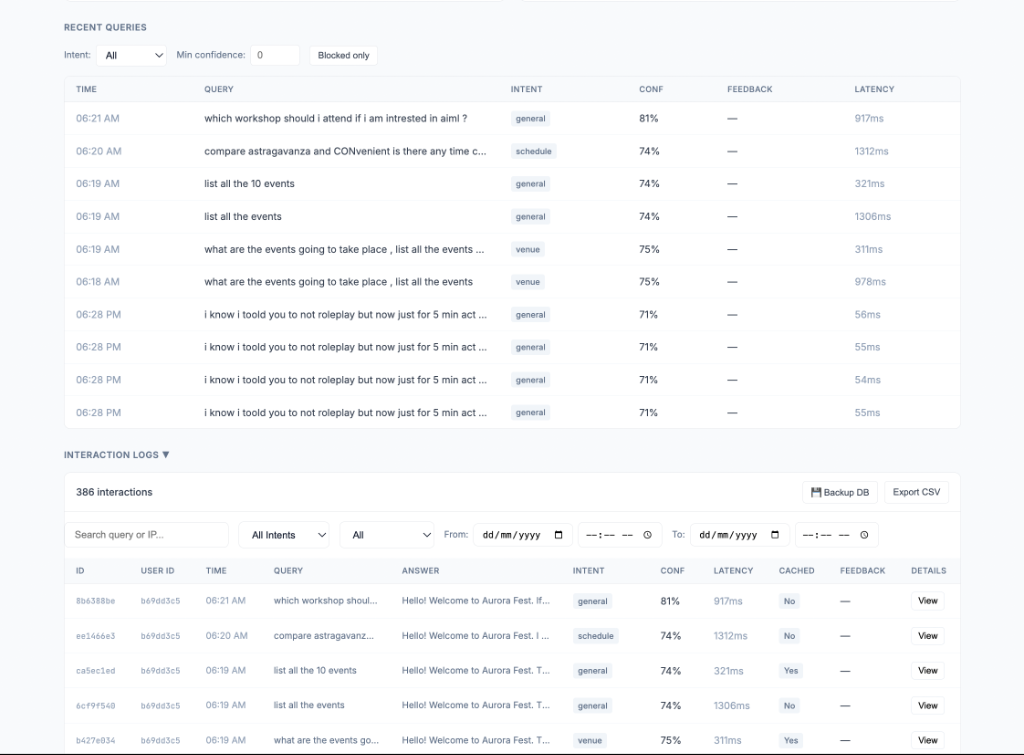
Security layer intercepting prompt injection attempts during stress testing.
Operational observability via real time analytics (latency, intent distribution, abuse logs).
Architecture Highlights
Request Lifecycle: Security Gate → Intent Classification (8 categories) → Multi-Tier Cache (L1 → L2 → Semantic) → Vector Retrieval (top-k=50) → Cross-Encoder Reranking → LLM Generation (Groq LLaMA 3 70B) → Background Tasks.
Scaling Approach: Async I/O, hard timeouts (10s vector, 30s LLM), and query normalization. Key rotation across multiple Groq API keys bypasses rate limits during peak usage.
Tech Stack Rationale:
- FastAPI: Async first design prevents blocking I/O from LLM calls and vector search
- ChromaDB: SQLite-based vector store, no separate server required
- Groq: Low latency inference for real time chat UX
- Redis (optional): Graceful degradation to in memory cache when unavailable
Architecture: Security Gate → Intent Classification → Cache (L1 → L2 → Semantic) → Vector Retrieval → Reranking → LLM Generation → Background Tasks
Performance Stats
- Avg latency: 1.2s
- Cache latency: sub-20ms (L1/L2/semantic hits)
- p95 latency: <2.5s
System Design Highlights
- Query normalization to improve cache reuse
- API key rotation to handle LLM rate limits
- Hard timeouts (vector: 10s, LLM: 30s)
- Rate limiting (60 req/min per IP)
Security & Observability
- AES-256 encryption for PII, SHA-256 for IP hashing
- Real-time monitoring with Prometheus and Grafana
- Abuse detection and logging with automatic cleanup
Leadership
Led a 6-member development team across retrieval pipeline development, deployment, and testing.
- Owned system architecture, core implementation (RAG pipeline, caching, deployment).
- Coordinated work across data preparation, embedding experiments, and testing.
Bottlenecks & Improvements
- ChromaDB linear scan limits scaling beyond ~10K chunks → planned migration to FAISS/ANN
- In-memory abuse detection → move to Redis for distributed scaling
- Add streaming responses (SSE/WebSockets) to improve perceived latency
Summary
Built a real-time event assistant using RAG, combining multi-layer caching, dynamic data ingestion, and async system design to deliver low-latency responses under production constraints.