GIC Insurance Analytics RAG
Grounded Analytics RAG for General Insurance Data
Project Overview
Objective: Build a grounded RAG system with citation enforcement for insurance premium analytics.
Data Coverage: FY24 & FY25 (April-October), 34 insurance companies, 9 segments
Core Value: The system focuses on domain-specific analytics and document generation, with RAG used as a semantic interface over computed insights rather than raw data.
Implementation Details
- LLM: Groq (Llama 3.3 70B)
- Vector Database: ChromaDB - Persistent semantic search
- Embeddings: sentence-transformers (all-MiniLM-L6-v2)
- Frontend: Streamlit - Rapid analytics interface (core complexity in data engineering)
- Data Processing: Pandas, NumPy
Grounding & Guardrails
- Closed knowledge base (49 documents)
- Low-temperature generation (0.1)
- Mandatory citations for numerical claims
- Template-based fallback when retrieval confidence is low
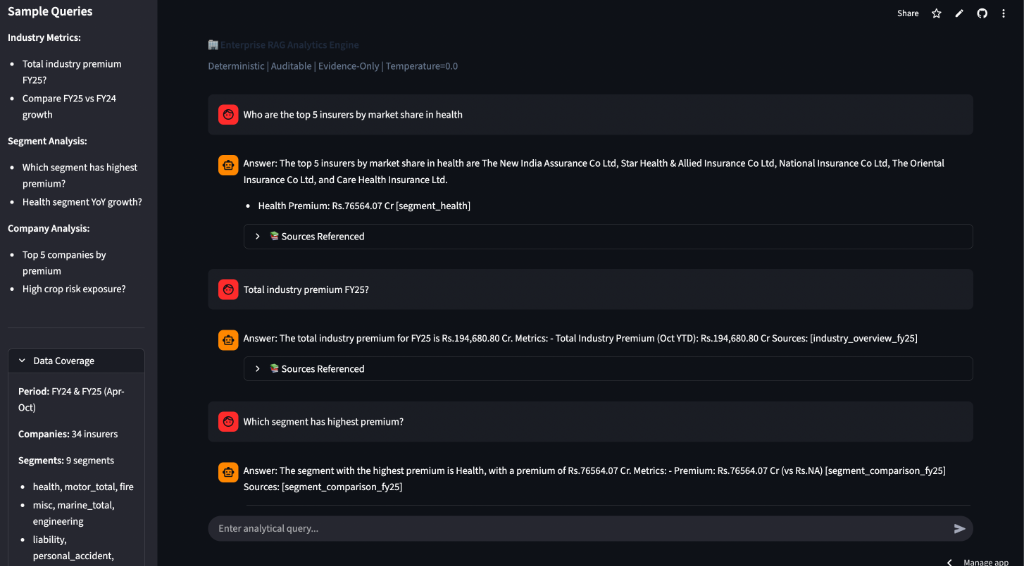
Step-by-Step Process
Phase 1: Data Collection & Preprocessing
Collected 7 monthly Excel reports (Apr–Oct 2025) with segment-wise premium data. Handled inconsistent formatting, multi-sheet files, and naming issues. Consolidated into master CSV with 2,380 records. Derived monthly premiums from YTD deltas.
Phase 2: Analytics & Insights Generation
Built analytics module with growth metrics, volatility analysis, portfolio concentration, and risk classifications (Health strategy, Misc segment risk). EDA performed to validate trends.
Phase 3: RAG Document Generation
Generated 49 semantic documents from structured data:
- Company Summaries (34): Premium, growth, top segment, concentration
- Segment Summaries (9): Market share, growth, trends
- Segment Rankings (9): Top 10 companies per segment
- Risk Classifications (4): Crop-risk, health strategy types
- Industry Overview, Growth Insights, Segment Comparison, Company Rankings
All documents citation-ready with document IDs.
Phase 4: RAG Engine Development
Components:
- Retrieval: Cosine similarity search (k=3) over 49 documents
- Generation: Groq (Llama 3.3 70B), temperature 0.1
- Guardrails: Similarity threshold check, template fallback, citation validation
Phase 5: Streamlit Interface
Built query interface with auto-generated knowledge base, chat history, and error handling.
Testing
- Analytics and rankings validated against source data
- RAG responses manually reviewed for citation correctness
- End-to-end queries tested via Streamlit interface
Technical Architecture
System Flow
The system follows a clear data flow from user query to final answer:
- User Query → Streamlit Interface
- RAG Copilot → Retrieval Phase (encode query, ChromaDB search)
- Retrieved Documents → Generation Phase (build context, Groq inference)
- Final Answer → Structured response with citations
Key Design Decisions
- Monthly premiums derived from YTD deltas
- Negative growth preserved for volatility analysis
- Mid-year company entries handled as new baselines
- Standard deviation used for volatility (interpretable units)
Results
- 2,380 records consolidated from 7 monthly reports
- 34 companies across 9 insurance segments
- 49 semantic documents generated
- 1–3s query latency
- All tested queries returned citation-backed answers
Future Enhancements
- Evaluation harness (precision@k, citation correctness)
- Hybrid retrieval (BM25 + vector with RRF)
- Incremental monthly ingestion